Sample Cache Questions
Question 1
- The access time of memory devices or cache components can be expressed in several ways. Explain how cache access time may be expressed.
- A line in a cache memory may be described as dirty. What does this mean?
- What is the meaning of the term write-
back when applied to cache memory? - Consider a cache memory that had an access of 1 clock cycle following a hit. If a miss occurs, the miss penalty is 100 cycles for a clean line and 200 cycles for a dirty line. On average, ten per cent of the lines are dirty. If the miss rate is 5%, what is the average access time of the memory?
- What is a write buffer in the context of cache memory?
- A write buffer is used in conjunction with the system described in part d. The write
buffer is able to eliminate 80% write-
back cycles. What is the new cycle time? - What is the speedup ratio of the system with the write back buffer compared to the original cache system?
Solution 1
- Access time can be expresses absolutely as time in nanoseconds; for example, the cache may have a 2 ns access time. However, since time in a digital system is quantized to units of the clock cycle, it is common to measure access time in terms of clock cycles. The shortest access time is 1 clock. Since most accesses take place to cache, some indicate the access time of main memory as a penalty with respect to cache; that is if the cache has a 2 cycle access time and main memory has a 25 cycle access time, the main memory can be said to have a 23 cycle penalty. Consider the following:
i. Clock 2 ns, cache 3.5 ns, main store 61 ns.
ii. Clock 2 ns, cache 2 cycles, main store 31 cycles
iii. Clock 2 ns, cache 2 cycles, main store penalty 29 cycles.
- A cache line may be read from or written to. Up to the point a line is written to and its data modified, it is called clean. When the data of an element in a cache line is modified by a write access, it is called dirty or modified. The significance of this is that a clean line does not have to be written back to memory when it is ejected from the cache, but a dirty line must be written back.
- When data is modified during a write cycle, both the copy currently in cache and the copy in memory must be updated. One technique is to modify only the data in the cache line when a write cycle takes place and there is a cache hit. When a miss occurs and the cache line is discarded, it must then be written back to memory (the same applies to a cache flush when a context switch takes place). Writing back a line to memory is called write back. An alternative to write back is write through where a write to cache results in a simultaneous write to memory in parallel.
- The access time of a memory with cache is h.tcache = (1 – h)tmem
If we express the time in terms of access penalties, miss ratio, and use clock cycles, we can express the same equation as
t.cache + m.tpenalty = 1 + 0.05 x (0.9 x100 + 0.1 x 200) = 1 + 0.05 x 110 = 1 + 5.5 = 6.5 ns.
- A write to cache mechanism is slow because the processor is held up while a line is being written to memory A write buffer provides a solution by queuing write to memory in a buffer this allows the processor to continue while buffered writes are being made in the background. In a write back cache, a new line can be fetched before the old dirty line has been written back.
- If we use a write buffer, we reduce the time lost to write back operations. The average access time now becomes
t.cache + m.tpenalty = 1 + 0.05 x (0.9 x100 + 0.1 x (100 + 0.2 x 100)) = 1 + 0.05 x 120 = 1 + 5.1 = 6.1 ns.
- g. Speedup ratio = unmodified time/new time = 6.5/6.1 = 1.07, a 7% improvement.
Question 2
- What is prefetching in the context of cache memory and what problem does it help alleviate?
- How can prefetching be improved to help support two-
dimensional data structures?
Solution 2
- Prefetching is a mechanism used to force the catch to update data before it is used. Doing this avoids the wait associated with a cache miss. A dummy access is performed before the data is required. No data is fetched to the CPU but the generation of a prefetch address forces a cache update.
- Data objects in a two dimension array are arranged in rows and columns. For example, if there are p elements per row, then an element in the same column but on the next row, will be p memory location on. Stride prefetching generates sequential addresses separated by a distance called a stride to access elements that are consecutive in data structures but separated by the stride distance in physical memory.
Question 3 (Virtual memory and cache)
Consider a computer with a 32-
a. How is the address partitioned between the page number and page offset?
b. How is the cache address partitioned between the byte offset, set number, and tag?
c. In this specific system, can the cache and TLB (page translation cache) be accessed concurrently, or must a page translation take place before a cache access can begin?
Solution 3
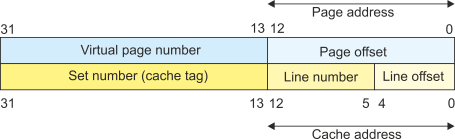
- The page size is 8 KB which is 213 bytes and is spanned by 13 address lines A0 to
A12. The remaining 19 bits A13 to A31 (32 -
13 = 19) select one of 2 19 possible virtual pages.
- The total cache size is 16 KB. However, because it is 2-
way set associative, there are two 8 KB caches operating in parallel. cache line is 32 bytes (2 5) and is spanned by A0 to A4. The number of lines in a cache is (cache size) divided by (line size) = 8K/32 = 213/25 = 28 = 256. Eight address lines A5 to A12 select a line number. The remaining address lines A13 to A31 provide a cache tag that defines the set number. - When a memory access takes place, the data has to be looked up in the cache. Simultaneously, it has to be looked up in memory. If the cache address fits within a page, then both accesses can take place in parallel. However, if the cache address is larger than the page address, then the cache cannot be searched until the correct page has been located (because you don’t know where to search). In this example (see the figure below) the cache address fits within the page address and the cache can be searched in parallel with the address translation.