Error Detecting Codes
This is an introductory article on the way in which errors occur in digital systems and how they are detected.
The reason we use digital systems is two-
Digital errors never occur in purely digital circuits. However, memory devices like
DRAM store data in an analog form as a charge on a capacitor and that charge can
be affected by events such as the passage of an ionizing particle through a memory
cell. It has been reported that such errors are of the order of once per month in
a 128 MB device. Flash memory is also subject to errors because the internal storage
mechanism can be damaged by repeated write and erase cycles. When digital data is
transmitted from point-
Clearly, errors are not a good thing. An error in a program can cause a crash or incorrect operation of the program. An error in data can be pretty meaningless (a bit dropped in a movie), inconsequential (a “the” in a block of text being changed into “thg”, or catastrophic (an error in a spacecraft navigation system).
There are two steps in dealing with errors. The first is error detection. Clearly,
you can’t do anything until you realize that you have erroneous data. The second
is error correction or recovery. Once you have found an error, you can either request
a new copy of the data, or you can correct it by means of an error-
Computers (i.e., digital systems) detect errors exactly like we do; for example, if you encounter the word qmick in English text, you know it is incorrect because there is no qmick in the English language. In other words, we have to encode data in such a way that any change from the correct value is obvious.
An n-
Parity
The simplest way of detecting a single error is called a parity bit. This is essentially the exclusive OR of all the bits of the word. Consider a word with four bits in total, P,C,B,A. We reserve one bit as the parity P, and the other three bits are C,B,A. If we define parity P as CÅBÅA, we can write all the legal combinations as:
P C B A
0 0 0 0
1 0 0 1
1 0 1 0
0 0 1 1
1 1 0 0
0 1 0 1
0 1 1 0
1 1 1 1
The parity bit is called an even parity because it ensures that the total number of 1s in the codeword is even. For the purpose of parity generation, number zero is defined as even.
Note how we have only eight legal combinations out of 16 possible combinations of
four bits, because one bit is no longer a variable; it’s a function of the other
three bits. We have taken a 3-
Suppose the original souceword is 010. The parity bit is 0Å1Å0 = 1 and the codeword is therefore 1010.
If we change a single bit of this codeword, we get 0010 or 1110 or 1000 or 1011. In each case the parity of the codeword is odd and the word is invalid (i.e., it does not correspond to a legal codeword). In other words, we can detect a single bit error.
If we get two errors in a codeword, the parity is preserved; for example, if the
codeword is 1010 and the leftmost two bits are changed, the result is 0110 which
is a valid codeword because the parity is even. Consequently, an error-
Where should the parity bit go in a word? It doesn’t matter. Each bit in a codeword
has the same chance of corruption. By convention, the parity bit is often the most-
The parity bit can be even (i.e., the total number of 1s in the word is even) or
it can be odd (the total number of 1s is odd). In principle, doesn’t matter whether
you use an even or an odd parity bit. However, if the sourceword is all zeros, the
parity bit will be zero and the codeword will be all zeros. Some engineers don’t
like an all-
The Hamming Distance
An important concept associated with error detecting codes is the Hamming distance between two binary words of the same length. The Hamming distance is a measure of how different the two words are.
Let’s look at a 3-
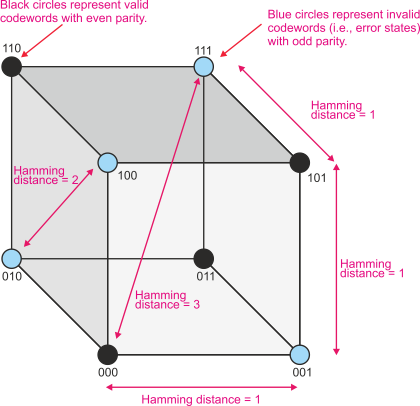
Figure 1 All possible combinations of a 3-
If you have two n-
X = 00001111
Y = 11111111 Hamming distance = 4
X = 10101011
Y = 10110011 Hamming distance = 2
Redundant Bits
Any error detecting code of n bits takes an m-
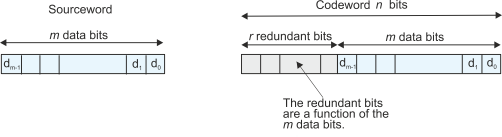
Figure 2 Data and redundant bits
Assume we transmit n-
If r check bits are added to the m message digits to create an n-
If we read a word from memory or from a communication system, we can check its location
within the n-
Errors
The theory of errors in digital systems marks the beginning of modern digital data transmission systems, information theory and coding. The father of information theory is Claude E. Shannon ad his pioneering work appears in the Bell System Technical Journal in 1948. However, Harry Nyquist also made a major contribution in 1924 when he discussed the rate at which data could be transmitted over a telegraph line.
Much of information theory uses the notion of the symmetric binary channel where the probability of a 0 changing to a 1 and a 1 changing to a 0 (due to noise) is equal. In a real system this may not be the case because the actual probability depends on the nature of the noise and the switching threshold of digital circuits. Similarly, random noise is often assumed to have a Gaussian distribution (that is, the amplitude of the nose has a Gaussian bell curve distribution). In practice, noise is often bursty; that is, errors occur in bursts. Error bursts occur because of the electromagnetic pulse generated by a lightning strike or an elevator motor starting.
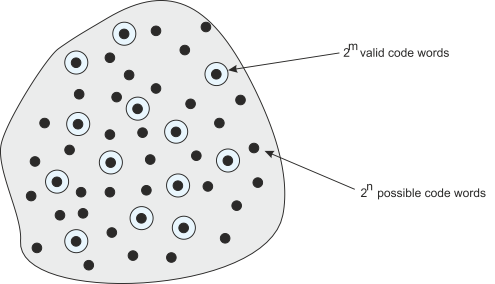
Figure 3 Code space
In the next section we look at an extension of error detecting codes, EDCs. These codes are error correcting codes, ECCs. Note that we should really write error detecting and correcting codes, but the term error correcting codes has become common.
 Error correcting codes
Error correcting codes