Register Windows
A fundamental conflict in instruction set design is the need for a compact instruction
format and the desire for a large number of on-
Today, the maximum number of on-
An important design feature of the Berkeley RISC architecture is the way in which it allocates register space to each new procedure. We will soon see that whenever a procedure is called, that procedure gets a new set of registers. Consequently, although the programmer can access only 32 registers at any instant, there is a different set of 32 registers associated with each procedure call.
Although only twelve or so registers are required by the invocation of a procedure
for parameter passing and local workspace, the successive nesting of procedures rapidly
increases the number of on-
Fortunately, although procedures can be nested to an arbitrary depth, the average behavior of programs does not demonstrate pathological behavior with respect to procedure nesting (except for programs involving recursion). Much RISC literature refers to research by Halbert and Kessler, [HalKes80], and Tamir and Sequin, [TamSeq83], demonstrating that most procedures are not nested to any great depth. These results indicate that it might be feasible to adopt a modest number of local register sets for a short sequence of nested procedures.
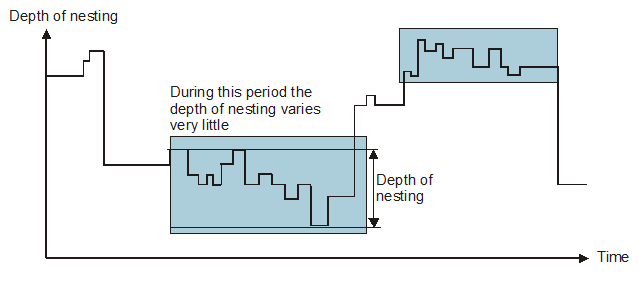
Figure 1 provides a graphical representation of the execution of a program in terms
of the depth of nesting of procedures. The vertical axis represents the depth of
the current procedure (up represents a procedure call and down a procedure return).
The horizontal axis represents time (i.e., the execution of the program). This diagram
is hypothetical, although it illustrates the procedure call-
The designers of the Berkeley RISC adopted a mechanism for implementing local workspace for up to eight nested procedures. They dedicated a set of registers to each of the eight procedures. Any further nesting forces the CPU to resort to external memory space for local variable storage, as we shall soon see.
Figure 1 The relationship between depth of procedure nesting and time
Register Space
For the purpose of our succeeding discussion, we are going to describe a procedure that calls another procedure the parent and the called procedure the child (this terminology is less ugly than using the terms caller and the callee). The parent may have its own parent, which is, of course, the grandparent of the child. Memory space used by procedures can be divided into four types:
Global space Global space is a region of logical address space that is directly accessible by all procedures. It is used to hold constants and data that may be required from any point within the program. Most conventional microprocessors have only internal global registers.
Local space Local space is a region of logical address space that is private to the current procedure. That is, no other procedure can access the current procedure’s local address space from outside the procedure. Local space is employed as working space by the current procedure.
Imported parameter space Imported parameter space holds the parameters imported by the current procedure from its parent. In Berkeley RISC terminology these are called the high registers.
Exported parameter space Exported parameter space holds the parameters exported by the current procedure to its child. In Berkeley RISC terminology these are called the low registers.
We are now going to look at how the Berkeley RISC takes a set of 32 registers and divides this set into the four groups we have just described.
Windows and Parameter Passing
One of the reasons for the relatively high frequency of data movement operations
in programs is the need to pass parameters to procedures and to receive them from
procedures. Any system that removes (or at least reduces) this two-
Figure 2 Structure of the RISC’s eight overlapping windows
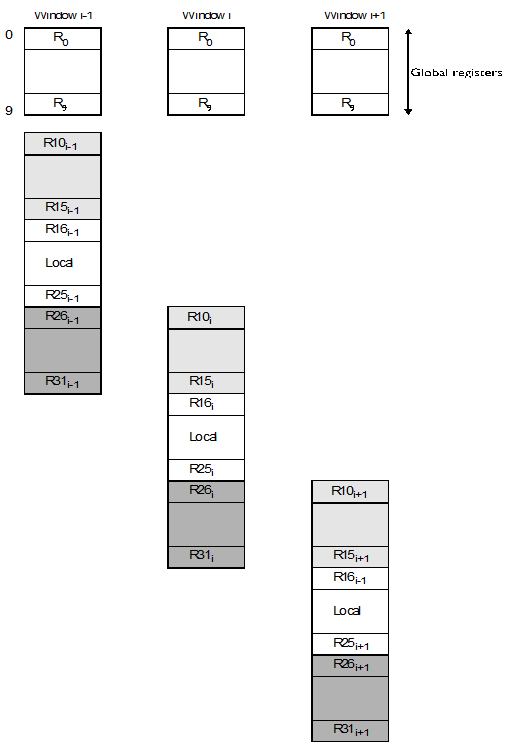
Suppose that the RISC processor is currently using the ith window set. A special-
All windows consist of 32 registers, R0 to R31, and each of these registers can be
addressed by a RISC I instruction that contains five address bits per operand field.
In this section we will use the mnemonics of the Berkeley RISC, wherever possible
when describing the operation of RISC architectures. A register-
The machine’s physical hardware places no restriction on the use of a procedure’s 32 registers. For example, programmers can employ parameter import/export registers as local variable space if they wish. However, it is considered good programming practice to employ the four register spaces in the manor intended by the chip’s architects. In other words, it would be regarded as poor practice to employ registers R26 to R31 as local variable space (even though there are no hardware limitations to stop you doing this).
Whenever a procedure is invoked by an instruction of the form CALLR Rd,<address>, the contents of the window pointer are incremented by 1 and the current value of the program counter saved in register Rd of the new window. The Berkeley RISC does not employ a conventional stack in external main memory to save subroutine return addresses.
Once a new window has been invoked (in figure 6 this might be window i), the new procedure sees a different set of registers to the previous window. Global registers R0 to R9 are an exception, since they are common to all windows. Register R10 of the child procedure corresponds to register R26 of the calling procedure. That is, the parent procedure’s register R26 is the same register as the child procedure’s register R10.
Suppose a procedure at level i calculates the sum of A and B, and then calls a procedure to subtract C from this sum (a trivial and unlikely example). The following code performs this action.
ADD R16,R17,R26 Add A (reg R16) and B (reg R17) in the procedure’s local address space
and deposit the sum in the procedure’s
export-
CALLR R18,SBTR Call a child procedure to execute the subtraction.
Register R18 in the child’s local space is used to hold the return address.
SBTR SUB R10,R16,R10 Subtract C (register R16) from the value of (A + B) imported in R10 and deposit the result in
R10 ready to export it to the parent procedure.
RET R18 Return to the parent procedure with the result in its register R26.
The return address to be loaded into the PC is in R18.
This example demonstrates that we don’t have to make a physical transfer of data
between a parent and a child procedure, as long as no more than six 32-
It is important to emphasize that the same register has different names in the parent
and child procedures. In this example the sum of A and B is located in R26 of the
parent procedure, which corresponds to register R10 of the child procedure. Since
registers have to be renamed each time they are used to pass data between procedures,
you will appreciate that RISC architectures are not well suited to the assembly language
programmer. In fact, there are several other reasons why RISC architectures are not
assembler programmer friendly. RISC architectures are, however, better suited to
the output of high-
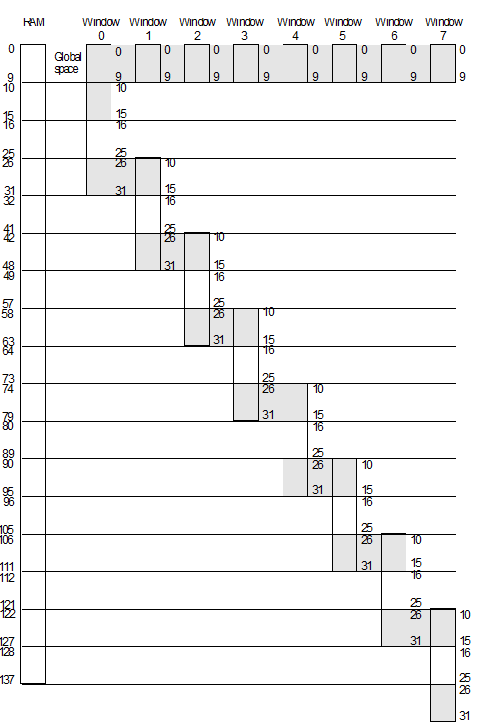
The complete structure of Berkeley RISC I’s window system is given in figure 3. On
the left hand side of the diagram is the actual physical register array that holds
all the on-
10 global registers + 8 x 10 local registers + 8 x 6 parameter transfer registers = 138 registers.
Figure 3 Structure of the RISC’s eight overlapping windows
Window Overflow
Unfortunately, the on-
If the number of procedure returns minus the number of procedure calls exceeds eight, window underflow takes place. Window underflow is the converse of window overflow and the youngest window saved in main store must be returned to a window. A program may run for relatively long periods when all procedure calls and returns can be catered for by the overlapped window mechanism. Only when window overflow occurs is it necessary to transfer data between the windows and the external memory. Of course, one corollary of this is that heavily nested procedures can severely limit the performance of Berkeley RISC type architectures to levels below that of more conventional microprocessors.
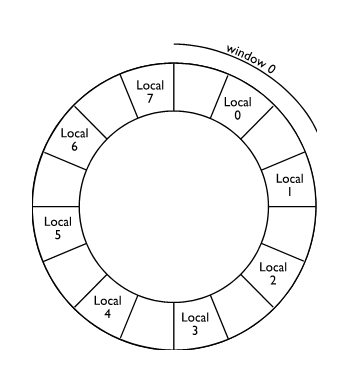
You can regard the window structure of the Berkeley RISC as a stack, figure 4. Each time a procedure is called, the stack pointer (i.e., the window register) is incremented and each time a return is made the window register is decremented. Since the first and last windows overlap, the window structure is arranged in a circular fashion as illustrated in figure 5.
Figure 4 The RISC’s window structure as a stack
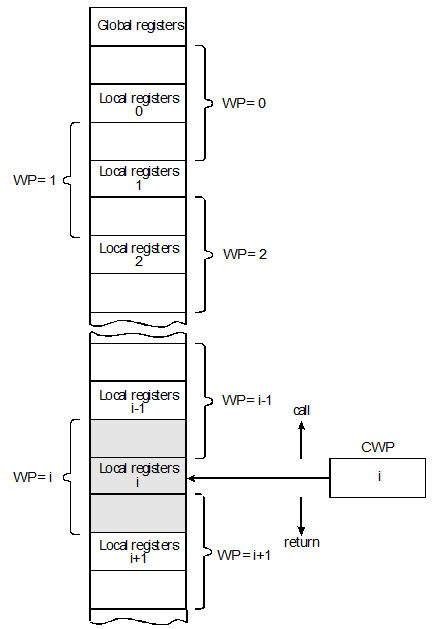
Figure 5 Logical arrangement of the RISC’s windows
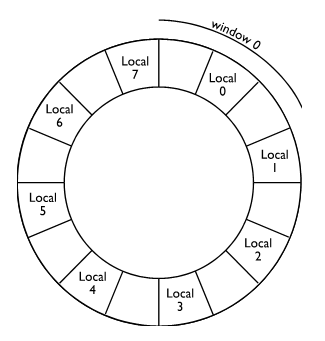
Consider now the effect of window overflow. Figure 6 demonstrates the situation in which windows zero to five are occupied. At first sight you might think that both windows six and seven are free. However, due the overlapping structure of the windows, window five overlaps window six, and window zero overlaps window seven. In figure 7 another procedure has been called and window six occupied. At this stage it is no longer possible to call a child procedure without taking some further action. If a procedure were called, window seven would be occupied and a clash would take place between the registers that window seven uses to pass parameters to its child and the registers that window zero uses to receive parameters from its parent (clearly, window seven is not the parent of window zero).
Figure 6 Windows 0 to 5 in use
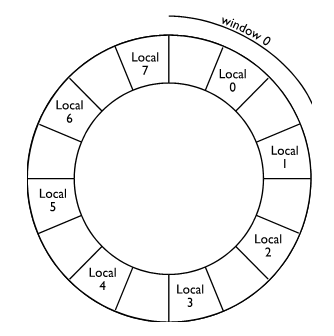
Figure 7 Windows 0 to 6 in use
The Berkeley RISC has two three-
When a window overflow trap occurs, it is necessary to make room in the window registers by saving the oldest window(s) in external store. As you can imagine, this operation takes some time to perform and can much reduce the processor’s throughput. Tamir and Sequin suggest that the best strategy is to save only one window at a time. Each time a window is saved, the SWP is incremented by one. A run of procedure calls (without intervening returns) causes a sequence of window overflow traps, each one resulting in the saving of a window and the incrementing of both the CWP and the SWP.
Each time a return from procedure is made, the CWP is decremented. If a decrement
causes CWP to become equal to SWP then underflow occurs, because all on-
We discuss windowing here because it was a significant innovation at the time RISC I and RISC II were being developed. However, the notion of windowing is orthogonal to RISC technology in the sense that you can apply windowing to a processor without affecting any other aspect of its architectures such as the instruction set or addressing modes. Moreover, windowing can be applied to any architecture.
When windowing was first introduced, it seemed to promise a massive increase in performance by offering lots of registers without the added penalty of increasing the instruction space by requiring more bits to specify a given register. It was believed that the penalty incurred in dealing with a window overflow or underflow exception was about 40 clock cycles. In practice things didn’t turn out that way.
One of the first commercial systems to implement windowed registers was the Sparcstation.
Running under SunOS 4.1.1 this system incurred a massive 280 cycles whenever a window
overflow/ underflow exception occurred. This penalty was incurred because of the
overall system architecture. The sequence of eight 32-
Alternative Window Strategies
The window strategy adopted by the designers of the Berkeley RISC is not the only way in which windows can be organized. Katevenis devotes some time to the discussion of alternative policies to the Berkeley RISC style windows in his thesis. Three topics covered by Katevenis are:
- Variable-
size windows - Dribble-
back windows - Cache memory versus windows.
The fixed-
A possible solution to the inefficient use of registers by Berkeley RISC processors is to allocate only those registers actually needed by each procedure. By taking this approach the designer can save silicon real estate and increase the processor’s speed. Just as importantly, reducing the average size of the windows means that less time need be spent on dumping/restoring windows following each window overflow/underflow.
Variable window sizes are very attractive in principle but are relatively complex
to realize. If fully variable window sizes are implemented, the current window pointer,
CWP, cannot be treated as a simple 3-
Not only is it more difficult to generate the address of a register within the register
file, but the problem of dealing with register overflow/underflow is magnified. A
Berkeley RISC architecture detects overflow/underflow by simply comparing the three-
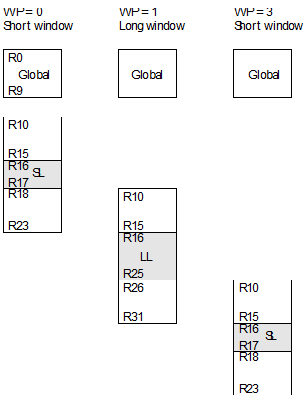
A compromise approach to the problem of optimum window sizes has been suggested by
Furht, [Furht88]. Instead of opting for the two extremes of fixed size or infinitely
variable size windows, Furht constrains the size of a window to one of two values.
Since 70% of procedure calls require eight or less arguments plus local scalars and
95% of procedures require 16 or less arguments plus local scalars, Furht proposed
two window sizes: large L-
Figure 8 demonstrates Furht’s two-
Figure 8 Overlapping two-
Dribble-
Instead of waiting for the occurrence of a window overflow or underflow, a so-
As in the case of variable sized windows, a dribble-